
파이썬을 이용해 사이트의 표데이터 쉽게 크롤링 하기
파이썬을 이용해 손쉽게 사이트의 표데이터를 크롤링 하는 법을 알아보겠습니다.
손쉽게 하는 방법을 알리고자 적은 글이니 추가 적인 방법을 원하는 학우는 마지막에 주소를 참고해주세요.
들어가기전에 설치해야할 것 입니다.
https://www.anaconda.com/products/individual#Downloads
위의 주소를 눌러 아나콘다를 다운로드합니다.

위의 Python 3.7 항목중에서 운영체제에 맞는 것을 다운받아 주시면 됩니다.
다운 받으신 후, 계속 NEXT를 눌러 설치해주시면 됩니다.
(자세한 Anaconda 설치방법은 https://docs.anaconda.com/anaconda/install/windows/ 을 참조 바랍니다.)
그 뒤에 왼쪽하단에서 Anaconda 를 검색해 Anaconda Navigator 를 실행합니다.
Jupyter Notebook을 실행합니다.
이후에 위의 사진과 같이 Python3 선택합니다.
이런 화면이 나옵니다. 이제 준비는 끝났습니다.
+버튼은 아래에 셀을 추가할 수 있고 ↑ ,↓화살표는 셀을 이동 할 수 있습니다.
디스켓모양은 저장버튼입니다. 가위모양은 잘라내고 그 우측은 복사 , 그 우측은 붙여넣기입니다.
저는 그냥 가위모양을 지우기로 쓰고있습니다. 잘라내고 다시 안붙여내면 되니까요.
스크립트가 저장되는 기본 경로는 C:\Users\사용자명 입니다.
위키피디아에서 FIFA World Cup에 대해 검색해보고 표 데이터들을 크롤링 해보겠습니다.
“표데이터”만 크롤링 하는 것을 배워보는 것입니다.
https://en.wikipedia.org/wiki/FIFA_World_Cup

import pandas as pd 라고 입력합니다. 이뜻은 pandas라는 패키지를 불러오는 것을 이제 pd라고 부른다는 뜻입니다.
입력 한 뒤 R 과 같이 Ctrl+Enter를 누르면 실행됩니다.( Shift+Enter를 누르면 그 블록을 실행하고 다음블록으로 넘어갑니다.)

R을 공부했던 학우들은 쉽게 알 수 있을 것인데, URL에 원하는 주소를 넣습니다. 따옴표 안에 넣는 것을 주의해야합니다.
pandas라는 패키지 import 하는 것을 아까 pd로 부르기로 했죠?
pandas 패키지 중에 read_html 명령어를 이용하여 URL의 내용 중 표 데이터에 해당하는 것만 찾습니다.
이때 뒤에 match는 해당하는 단어를 뜻합니다. 저는 우승자(우승국가)를 알고싶어 “Champions”가 들어간 표 데이터만 추출하기로 했습니다.
print는 말 그대로 출력하는 것입니다. 원하는 글을 출력할 수 있습니다.
len은 갯수를 의미하는데 python에선 1부터 시작하지 않고 0부터 시작합니다. 예를들어 0,1,2,3 … 이렇게요.
len(tables)는 저 URL에 “Champions” 이라는 내용을 포함한 표 데이터의 갯수를 의미합니다.
한 번 저 코드를 돌려볼까요?
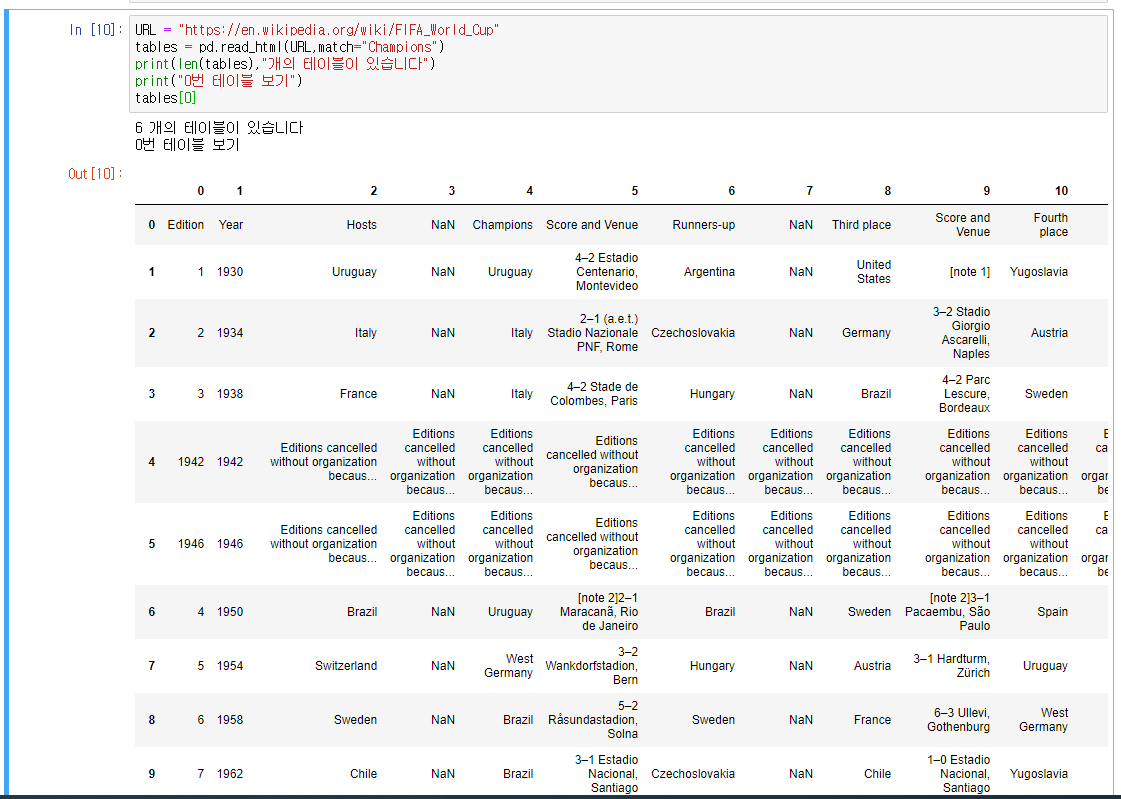
2개의 테이블이 있다고 나옵니다. table[0]과 table[1]이 있겠죠. R은 1부터 시작하지만 python은 0부터 시작하니까요.
table[0]를 봤더니 위 그림 처럼 각 년도별 Champions 와 Hosts (주최 국가) 등이 나옵니다. (25번의 행까지 있는데 사진에는 9번까지 담았습니다.)
가장 저 URL 주소에서 첫번 째 표데이터를 찾으려면 어떻게 할까요?
match=”단어”를 지우고
import pandas as pd
URL = “https://en.wikipedia.org/wiki/FIFA_World_Cup”
tables = pd.read_html(URL)
print(len(tables),”개의 테이블이 있습니다”)
tables[0]
이렇게 하면됩니다.
그리고 디스켓 모양을 눌러 저장하면됩니다.
첫번째 파일을 엑셀파일로 저장하고 싶으시면
df=tables[0]
df.to_excel(‘abc.xlsx’) 이렇게 추가하면됩니다.
df.to_excel에서 df는 table[0]을 가르킵니다.
table[0]을 df2로 저장했다면 df2.to_excel(‘파일이름.xlsx’)이렇게 하면 됩니다.
match를 제외하고 다양한 인수들을 보고 싶으면 아래 주소를 참고해주세요.
https://pandas.pydata.org/pandas-docs/version/0.23.4/generated/pandas.read_html.html